Why Do Representations Collapse? Frustration and Dynamics from a Minimal Model
This post introduces our recent work:
A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics (arXiv)

In modern deep learning, self-supervised learning (SSL) has shown strong generalization by extracting structured information from unlabeled data. Its goal is to learn a well-organized representation geometry in which similar inputs cluster together, while dissimilar ones stay apart.
Yet this process also has a well-known failure mode: representation collapse. When collapse occurs, representations lose their ability to distinguish between samples, and data points that were once separated contract toward one another and eventually overlap in representation space, causing the model to fail.
Although many practical techniques have been developed to prevent collapse, the underlying dynamics are still not well understood. In this work, we step outside the usual analytical framework and build a minimal dynamical model directly in representation space, abstracting away the details of network architecture and parameters. From this perspective, a classical concept from statistical physics, frustration, emerges as a natural way to describe the core mechanism behind representation collapse.
1. Empirical Observation: Anomalous Behavior Across Time Scales
Before introducing the theoretical model, we first examine a concrete training phenomenon.
Rather than using the standard setup for classification, we work in a generative representation learning framework: both data and labels are mapped into a shared representation space, often called the embedding space in practice. In this setting, collapse can be characterized directly through representation geometry.
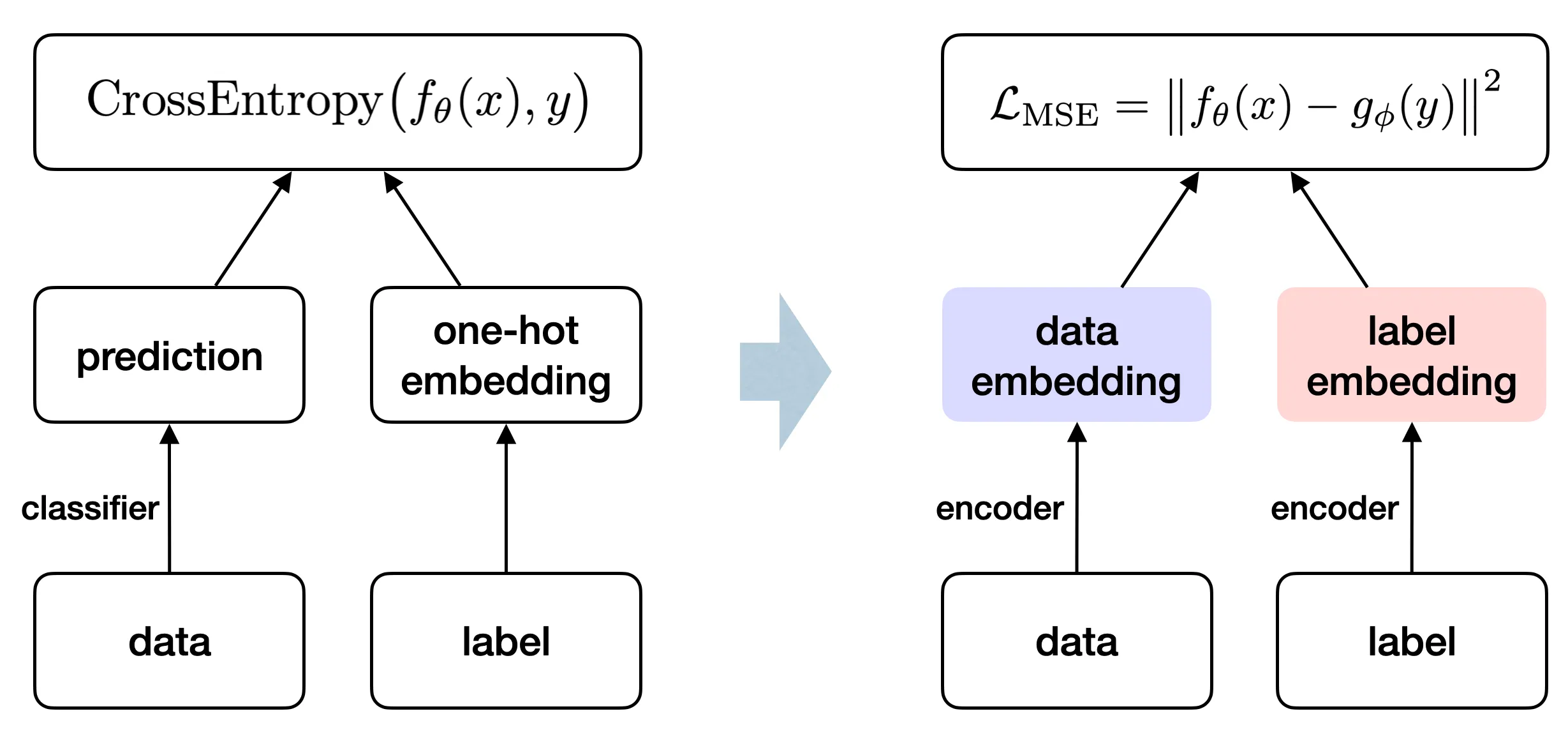
When we evaluate a classifier on the training set, we usually expect accuracy to rise as the training loss falls. But if we also track another metric, the minimum distance between classes in representation space,
we find a striking two-stage pattern.
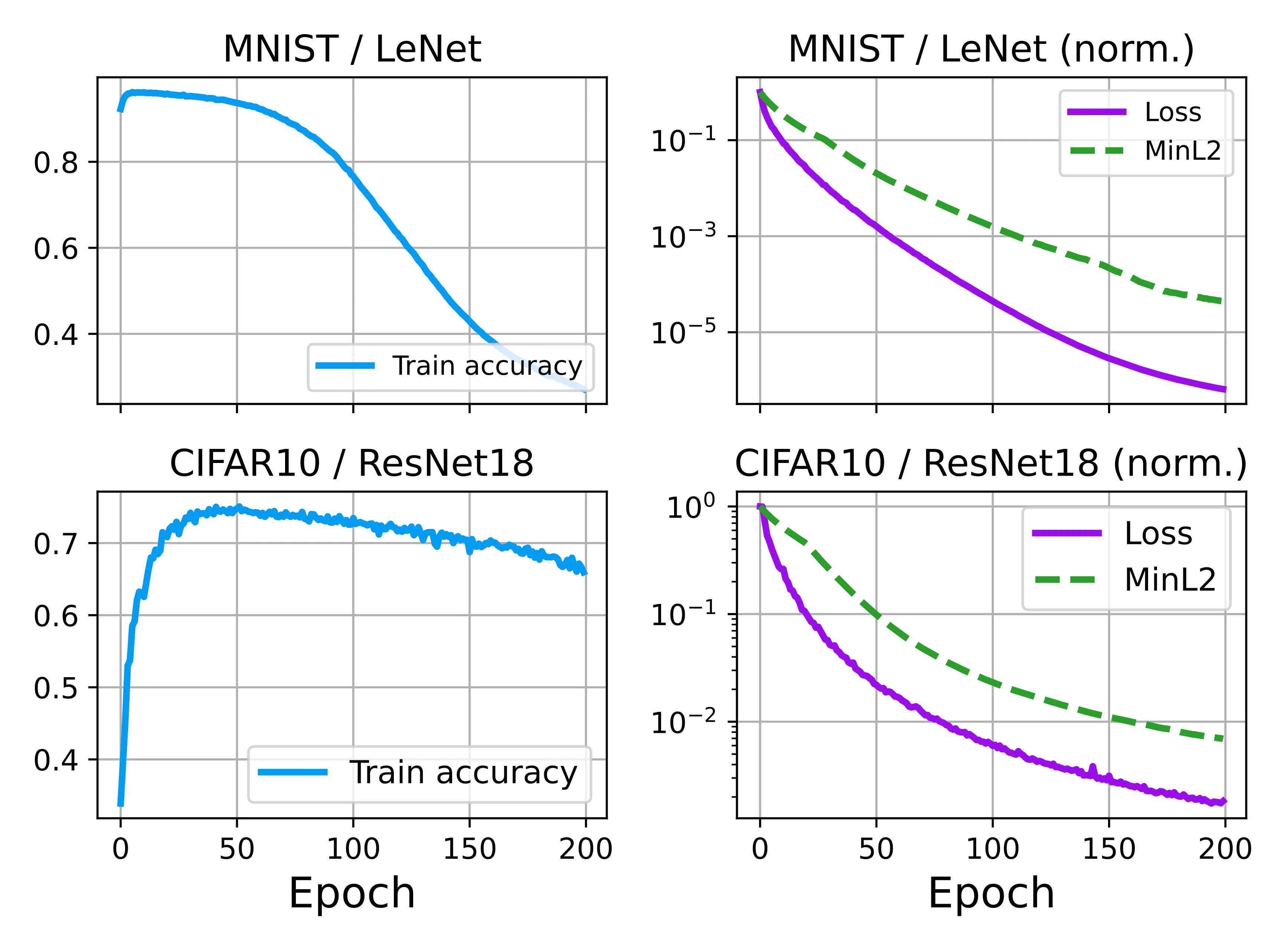
As the figure shows, accuracy rises quickly at the beginning of training. But after a certain critical point, it begins to fall even though the overall training loss keeps decreasing. More importantly, the inter-class distance (MinL2), after changing only slowly at first, then starts to shrink steadily and substantially; note that the vertical axes in the two plots on the right are logarithmic. In other words, representations from different classes drift irreversibly toward one another in the later stage of training, eventually collapsing.
Of course, this phenomenon is not inevitable. In practice, a simple yet crucial technique—Stop-Gradient—can effectively prevent representation collapse.
Operationally, Stop-Gradient keeps the forward-pass values in the loss, but blocks their gradients during backpropagation, so that branch does not contribute to parameter updates. In other words, the model can still “see” those representations without trying to modify them.
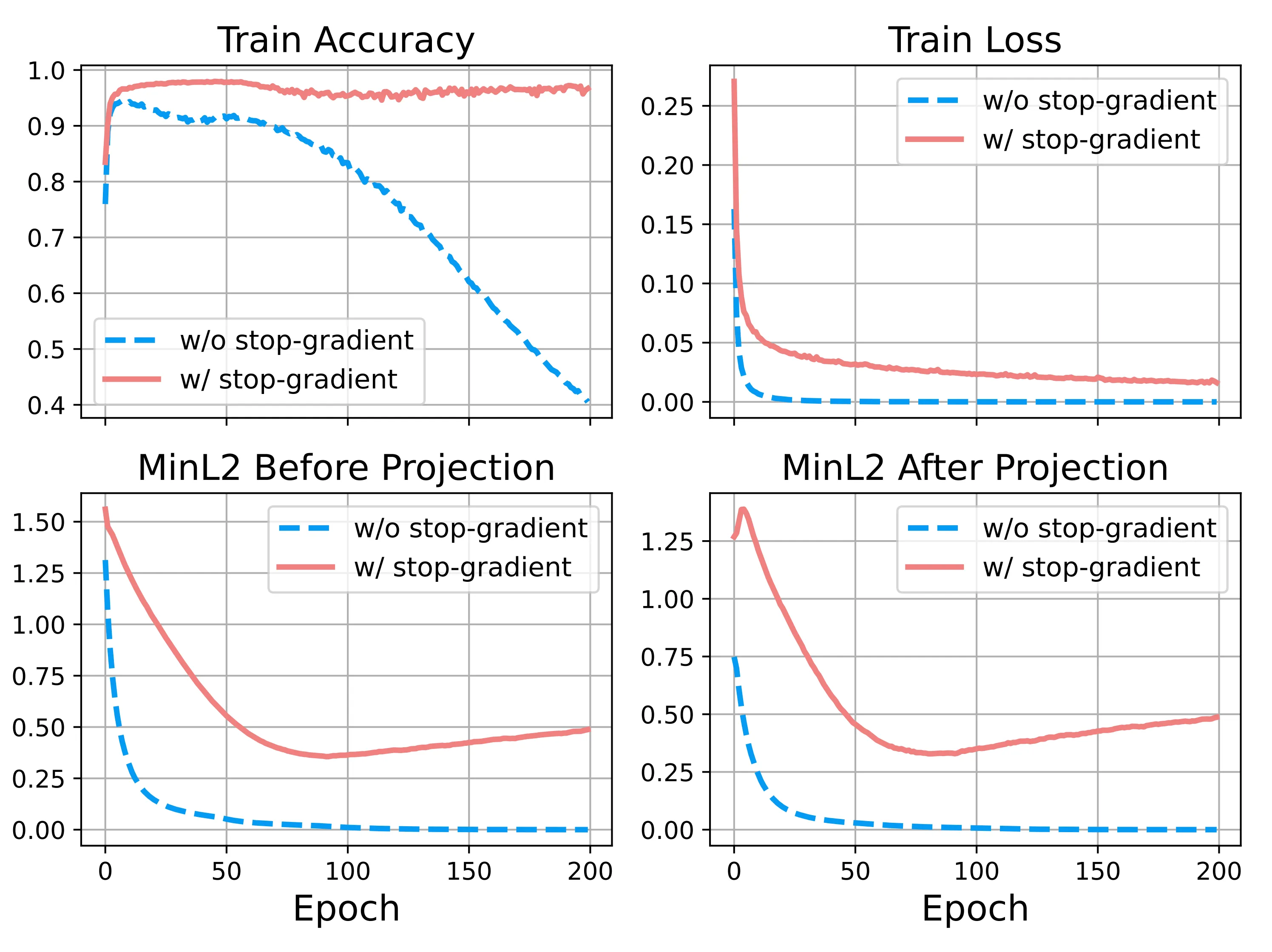
Under the same setup, we add a shared projection layer and compare training with and without Stop-Gradient. Early on, the two cases look almost identical: accuracy rises quickly, and the inter-class distance evolves in tandem. Later, however, their behavior clearly splits.
Without Stop-Gradient, accuracy reaches a peak and then gradually declines, while MinL2 keeps decaying toward zero, reflecting the progressive collapse of the representations. With Stop-Gradient, by contrast, accuracy stays high and stable, while MinL2 stops decaying and saturates at a finite value, showing that geometric separation between classes is preserved.
This indicates that representation collapse is not an inevitable outcome of training, but is closely tied to the specific training dynamics. The seemingly simple Stop-Gradient mechanism is sufficient to alter the long-term evolution of the system.
2. Physical Modeling: Minimal Dynamics and Frustration
To capture this phenomenon, we construct a minimal gradient-flow dynamical system. In this framework, we set aside the specific model architectures
In the ideal case, where all samples can be perfectly assigned to their respective classes, dynamical analysis shows that each class evolves independently and converges to a stable configuration with finite separation. This implies that alignment optimization alone does not lead to collapse.
So where does representation collapse come from? To explain this phenomenon, we introduce a key concept—frustration.
In practical representation learning, especially for classification, there is often a subset of “difficult” samples. Because of data noise, intrinsic class overlap, or limits in model expressiveness, these samples cannot be assigned consistently to a single class. Instead, they are pulled toward multiple classes in representation space, creating a set of competing alignment constraints.
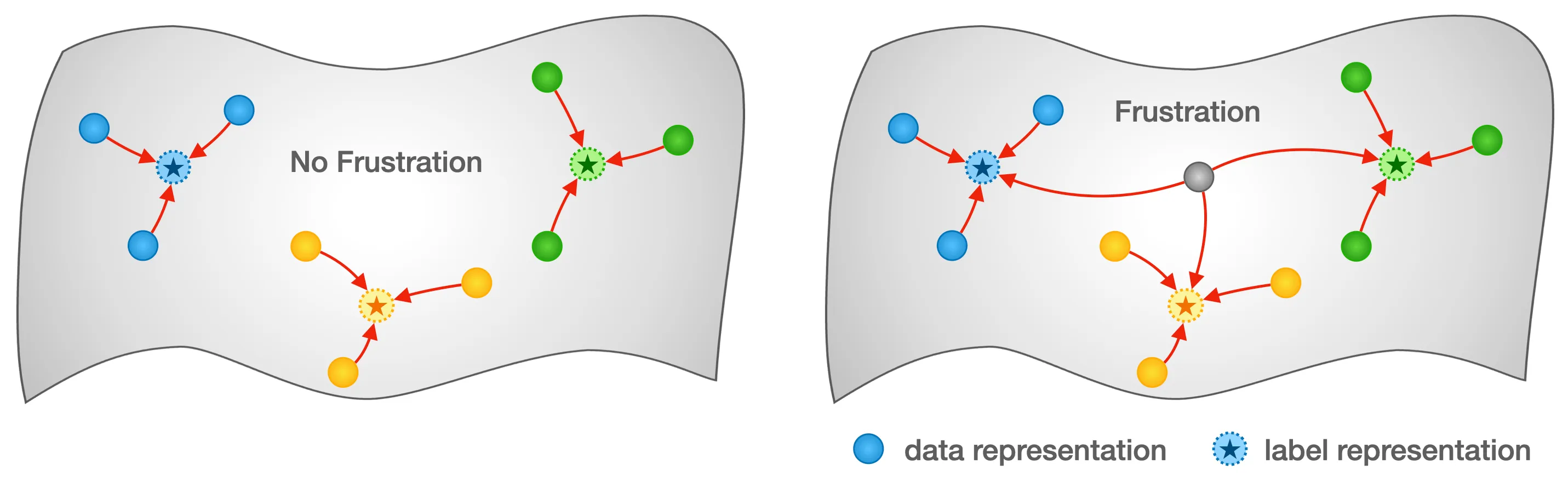
In our minimal model, we abstract away the details of the data and the network and represent this mechanism directly in representation space. Specifically, we designate a fraction
From the perspective of statistical physics, this corresponds to a typical frustrated system: local interactions in the system cannot be simultaneously satisfied, and thus there is no global configuration that can minimize all local energies at once.
It is this intrinsic inconsistency that introduces additional tension, making the evolution of the system no longer a simple independent convergence, but rather exhibiting more complex structural behavior.
3. Dynamical Analysis: Invariant Subspaces and Time-Scale Separation
To analyze how the system evolves, we rewrite training, that is, gradient descent, as dynamical equations for the representations. In the continuous-time limit, the evolution of
For the MSE loss function we consider, this dynamics has a simple structure: each representation is “pulled towards” its alignment targets, forming a coupled linear system.
We now analyze the dynamics with and without frustration.
3.1. Independent Evolution Without Frustration
First consider the ideal case
Integrating these equations gives a clear analytical picture:
- Sample-level convergence: all sample representations
converge exponentially fast toward their class representation ; - Label-level stability: the class representations are not fixed from the outset, but because they are influenced only by samples from the same class, they eventually settle into positions determined by the initial distribution.
Thus, in the absence of frustration, different classes do not interact, and the system converges to a stable classification manifold with finite inter-class separation. This mathematically proves that collapse is not an intrinsic property of the system.
3.2. Frustration-Induced Dynamical Collapse
When frustration is introduced with
To analyze this coupled system, we utilize permutation symmetry to rigorously decompose the high-dimensional degrees of freedom into three orthogonal invariant subspaces:
- Sector I (Sample Fluctuations): Describes the degree of dispersion within the same class, i.e.,
and . The dynamics in this subspace is dominated by alignment terms and does not introduce instability related to frustration. Samples still converge to their respective class centers on a relatively fast time scale. - Sector II (Inter-Class Bias): Describes the deviation of each class representation from the overall mean, i.e.,
and . This subspace characterizes the relative geometric structure between classes, and is the core degree of freedom that determines whether representations can maintain separation or collapse. - Sector III (Global Translation): Describes the overall movement of all representation centroids
. This subspace contains two decaying modes and one zero mode, which only change the overall position without affecting the relative relationships between classes, thus having no substantial impact on representation geometry and final classification performance.
In sector II, the dynamics exhibits a key structure: the evolution matrix has eigenvalues
In the typical limit of classification problems (large sample size
This phenomenon can be directly observed in numerical experiments:
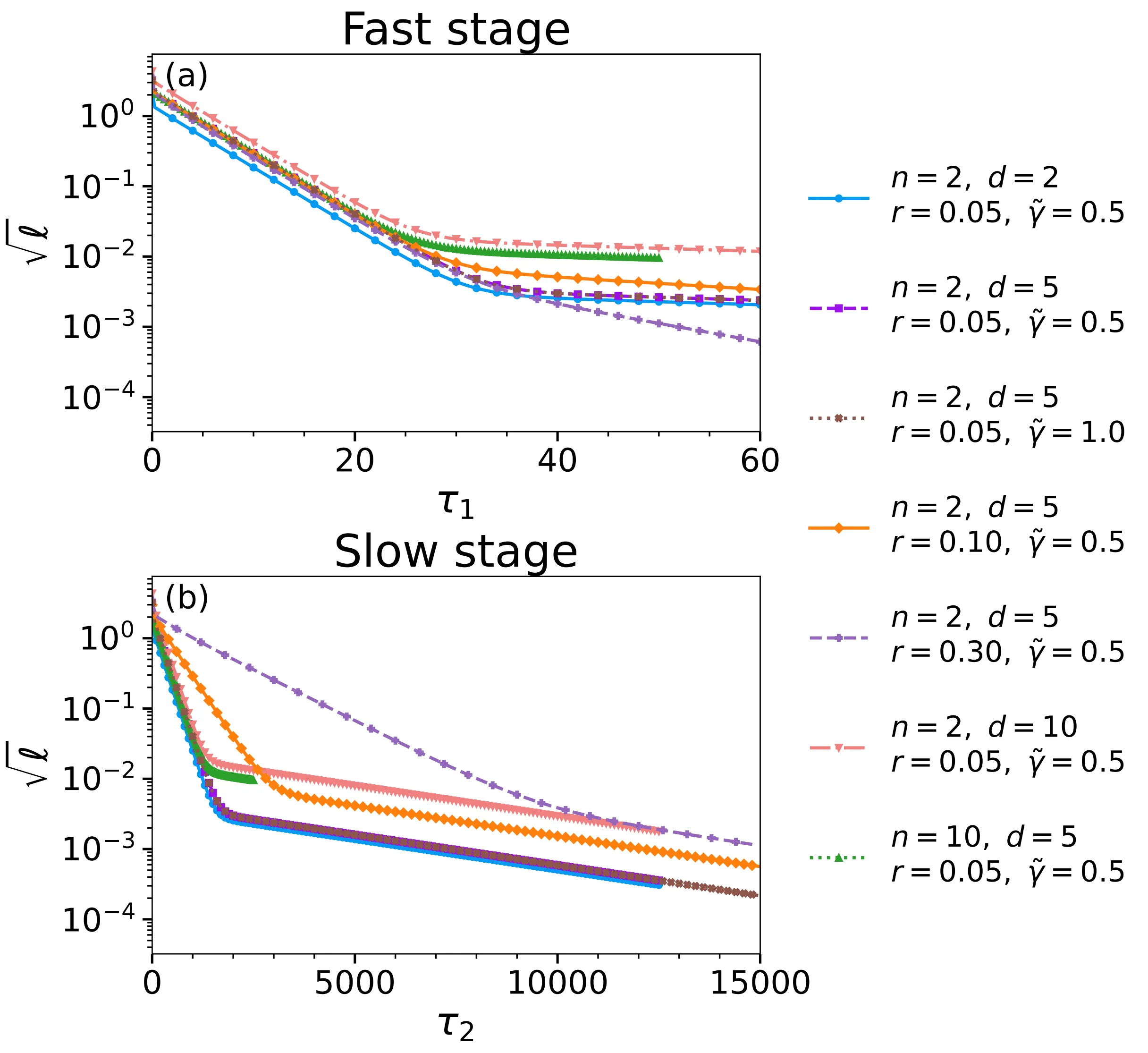
More specifically, one mode evolves quickly, at a rate that scales with system size (
At the same time, frustration introduces another mode, a “slow mode,” whose rate is controlled only by the frustration ratio (
Driven by this slow evolution, the geometric separation between classes is gradually eroded, and the representations contract bit by bit, ultimately leading to overall collapse. The entire process is not a sudden collapse, but rather an inevitable result of a small amount of frustration accumulating and gradually dominating over long time scales.
4. Breaking Symmetry: Stationary Analysis and Time-Dependent Evolution
Some SSL frameworks such as SimSiam and BYOL are strikingly simple. They do not rely on negative samples; instead, a projection layer together with an asymmetric Stop-Gradient operation is enough to preserve discriminative representations. This design has been highly successful in practice, but the mathematical reason for its success is often obscured by architectural complexity. In our minimal model, we try to give a rigorous explanation of why Stop-Gradient works.
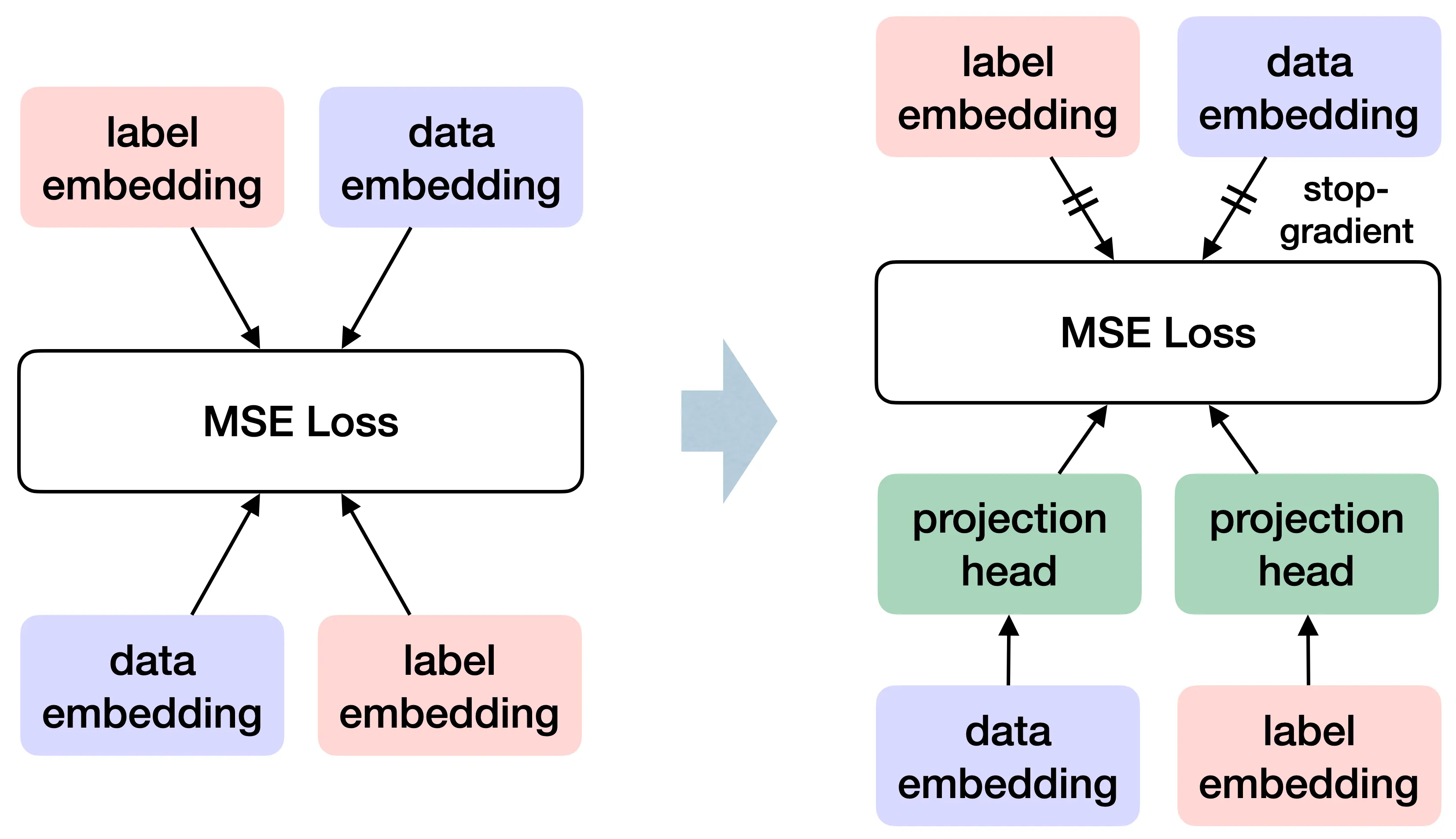
To analyze this process, we introduce a linear projection matrix
4.1. Geometric Constraints Under Symmetric Gradient Feedback
We first examine a key question: can simply adding a projection head
Without Stop-Gradient, the gradient feedback between data and label representations is fully symmetric. The system therefore still evolves as a conservative flow that seeks to minimize a global energy. By imposing the steady-state conditions (
where the matrix
It’s clear that in order to maintain geometric separation between classes, i.e., to have a non-zero bias
This contradiction gives a clear theoretical criterion: under symmetric gradient feedback, the spectrum of the operator cannot satisfy the condition needed to preserve finite separation between classes. As a result, even after introducing additional projection degrees of freedom, the system can only admit the trivial solution
4.2. Non-collapsing Subspace in Asymmetric Dynamics
The key to changing this outcome is the Stop-Gradient operation.
From the perspective of physics, Stop-Gradient does not modify the energy landscape defined by the loss function, but rather changes the vector field induced by the gradients. Since Stop-Gradient truncates one of the feedback paths, the system no longer performs gradient descent along the negative direction of the energy function, thus becoming a non-conservative dynamical system.
This asymmetric evolution completely breaks the geometric constraints imposed by bidirectional coupling. Under steady-state conditions, Stop-Gradient greatly simplifies the dynamical equations and allows us to derive a closed-form relation between the projection operator
This identity reveals that the eigenvalue spectrum of
Sector: In this eigenspace, the equation gives a projection relation , indicating that the representations of all classes are forcibly mapped to the global mean, representing a tendency for the system to contract representations towards the overall centroid. Sector: This is a key non-trivial solution space. Analysis shows that within this sector, . This means that any feature component that can distinguish different classes (i.e., the bias ) is strictly confined to the direction with eigenvalue .
Under Stop-Gradient dynamics, the spectrum of

Through the above spectral analysis, we not only theoretically confirm the necessity of Stop-Gradient, but also rigorously prove from the perspective of dynamical stability why it can serve as a symmetry-breaking mechanism to prevent representation collapse.
4.3. Time-Dependent Evolution in the DMFT Perspective
In the stationary analysis above, we have seen how Stop-Gradient opens up a non-collapsing feature subspace for the system. However, the natural follow-up question is: how does the system evolve step by step toward this steady state throughout the long training process?
Once we introduce a learnable projection matrix
To describe this time-dependent evolution, we draw on ideas from Dynamical Mean-Field Theory (DMFT) and formulate a set of Dyson-type integral equations. In this picture, we no longer track the absolute trajectory of each variable separately. Instead, we treat the Gram matrix
This set of DMFT-style integral equations provides a rigorous theoretical foundation for understanding the complete time-dependent evolution of asymmetric dynamics induced by Stop-Gradient. However, due to the nonlinearity in the effective medium, further dimensional reduction and exact analytical solution of these integral equations present significant challenges. In this work, we primarily establish this framework and conduct qualitative analysis using it. How to rigorously extract low-dimensional effective dynamics from these equations remains an important direction for future work.
5. Empirical Verification: Teacher-Student Model
In the minimal model above, we stripped away the network architecture and treated the representations themselves as freely moving microscopic degrees of freedom. This is mathematically elegant, but it leaves an important question: once we restore the parameterized mapping from inputs to representations, do the frustration-driven collapse mechanism and the protective effect of Stop-Gradient still persist?
To answer this question, we construct a controlled Teacher-Student Model.
We use a fixed linear “teacher model” to generate high-dimensional (e.g.,
From each class, we randomly select a fraction
When we train this student network using standard gradient descent, we successfully reproduce the time-scale separation in dynamics:
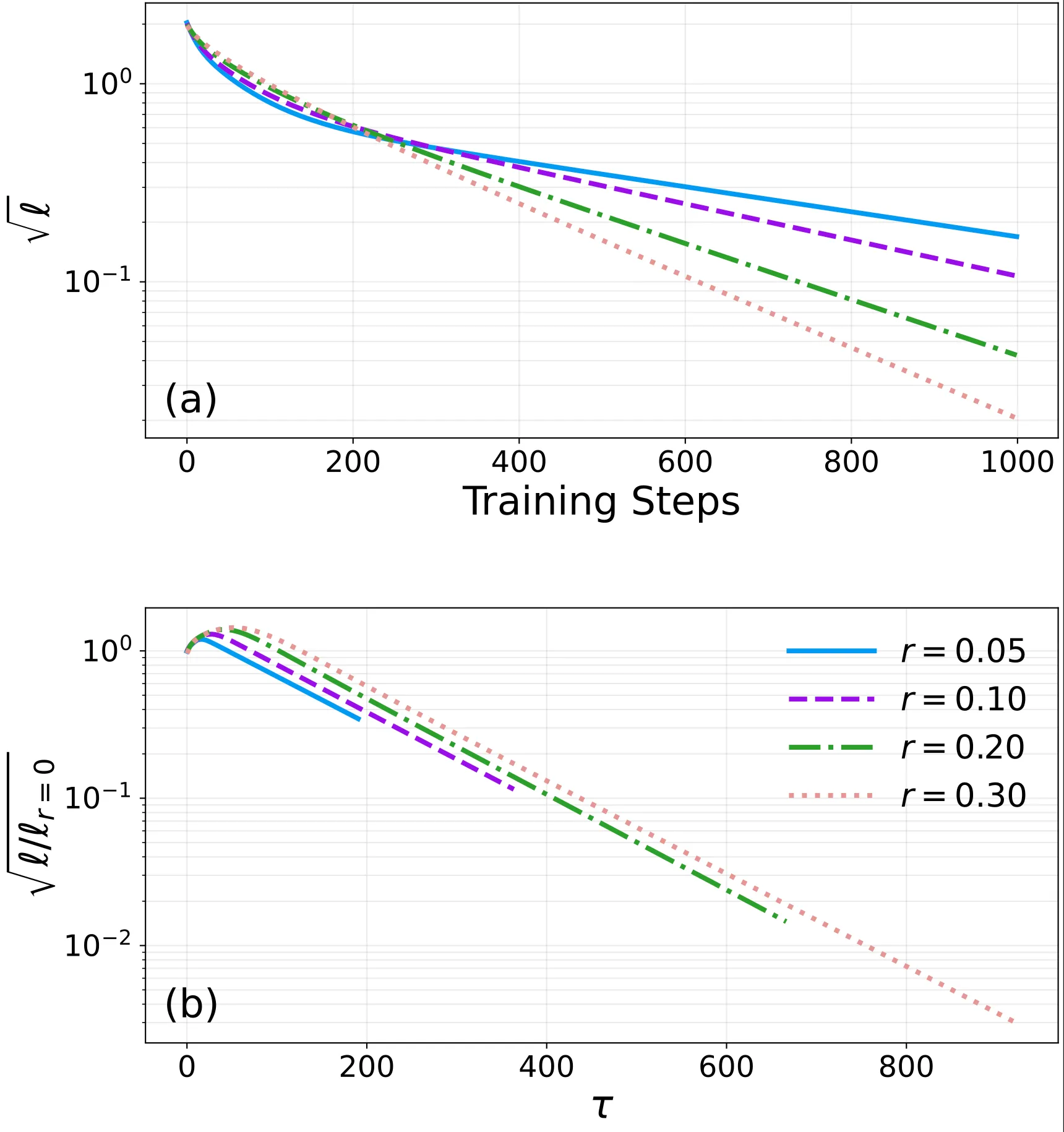
In the early stages of training, loss decreases rapidly, corresponding to the model learning clearly distinguishable clean samples. However, as time progresses, evolution inevitably enters a slow decay phase. If we rescale the time coordinate according to the effective frustration ratio
This result demonstrates that in real parameterized networks, the time scale governing representation collapse is still determined by the frustration ratio in the system.
Finally, we introduce the projection layer and Stop-Gradient mechanism into this teacher-student model.
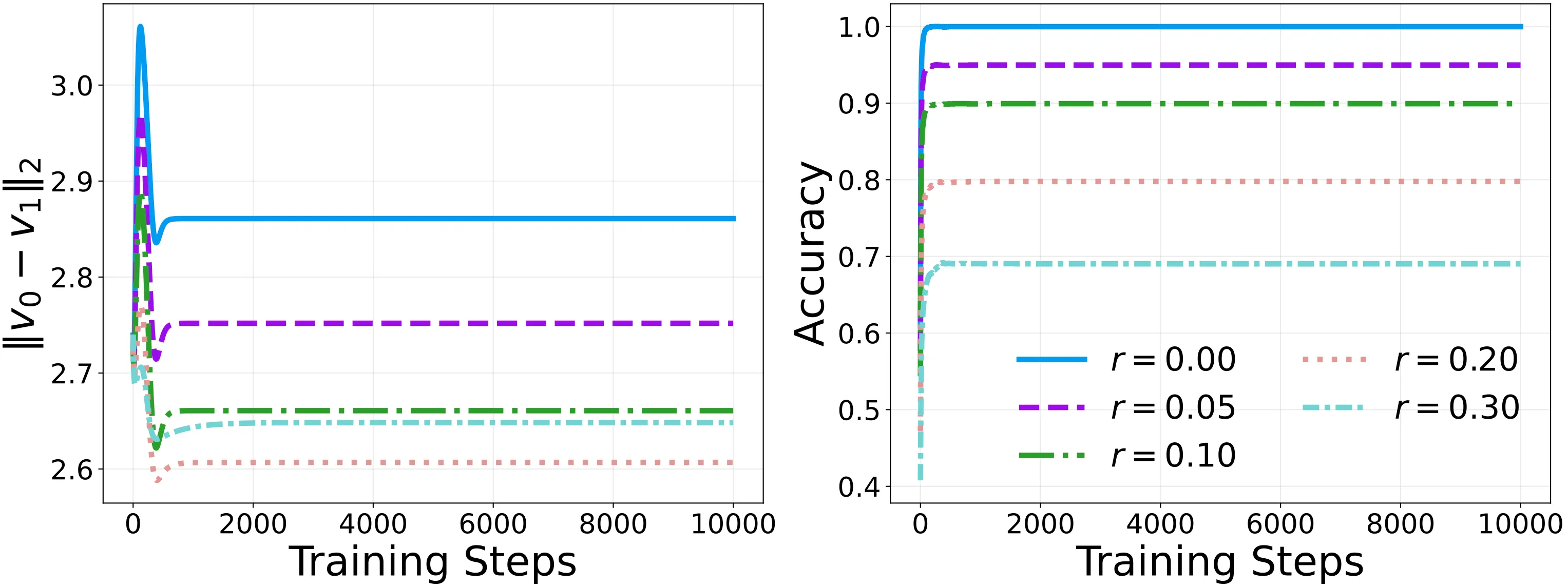
The experimental results are as clean as the theory predicts. Under frustration, the inter-class distance MinL2 undergoes a brief initial adjustment, quickly rebounds, and then remains stable, preventing representation collapse. More importantly, the model’s classification accuracy approaches the ideal upper bound of
Without Stop-Gradient, linear models have a built-in scale invariance: the network can keep reducing residuals simply by uniformly shrinking the overall parameter scale, which inevitably drives the inter-class distance toward zero. Stop-Gradient’s asymmetric dynamics blocks this shortcut. It not only opens up a non-collapsing feature subspace in geometric terms, but also preserves the macroscopic discriminative structure of the representation manifold in the parameterized network.
Conclusion
One of the central challenges in understanding modern deep learning is that huge parameter counts and complex nonlinear architectures often obscure the underlying dynamics. In this work, we take the opposite approach: instead of getting entangled in microscopic model details, we start directly from representation space and build a clean, minimal model.
Our results suggest that representation collapse, a typical macroscopic failure mode, and the mechanisms that prevent it are not governed by complicated microscopic parameter settings, but by a small number of parameters and symmetries. This perspective suggests that many puzzling macroscopic phenomena in modern AI models are in fact analytically accessible. By looking beyond code-level and architectural details, we can uncover mathematical explanations that are both simple and deep.
We hope that this physical perspective, which distills complex networks into minimal dynamical systems, can offer simple but powerful insights into how current AI models are trained and how those training dynamics might be improved.
If you find this work inspiring or helpful, we welcome you to cite our paper!
@misc{yao2026modelcollapse,
title={A Minimal Model of Representation Collapse: Frustration, Stop-Gradient, and Dynamics},
author={Louie Hong Yao and Yuhao Li and Shengchao Liu},
year={2026},
eprint={2604.09979},
archivePrefix={arXiv},
primaryClass={cond-mat.dis-nn},
url={https://arxiv.org/abs/2604.09979},
}